About me
I’m a third year Computer Vision PhD student at ISIR lab from Sorbonne University and Thales CortAIx Lab under the supervision of Nicolas Thome. I am currently working on visual representations, focusing on the use of foundation vision encoders for dense vision tasks. My research interests include diffusion models, self-supervised and weakly supervised learning and feature upsampling.
News
Publications
2025
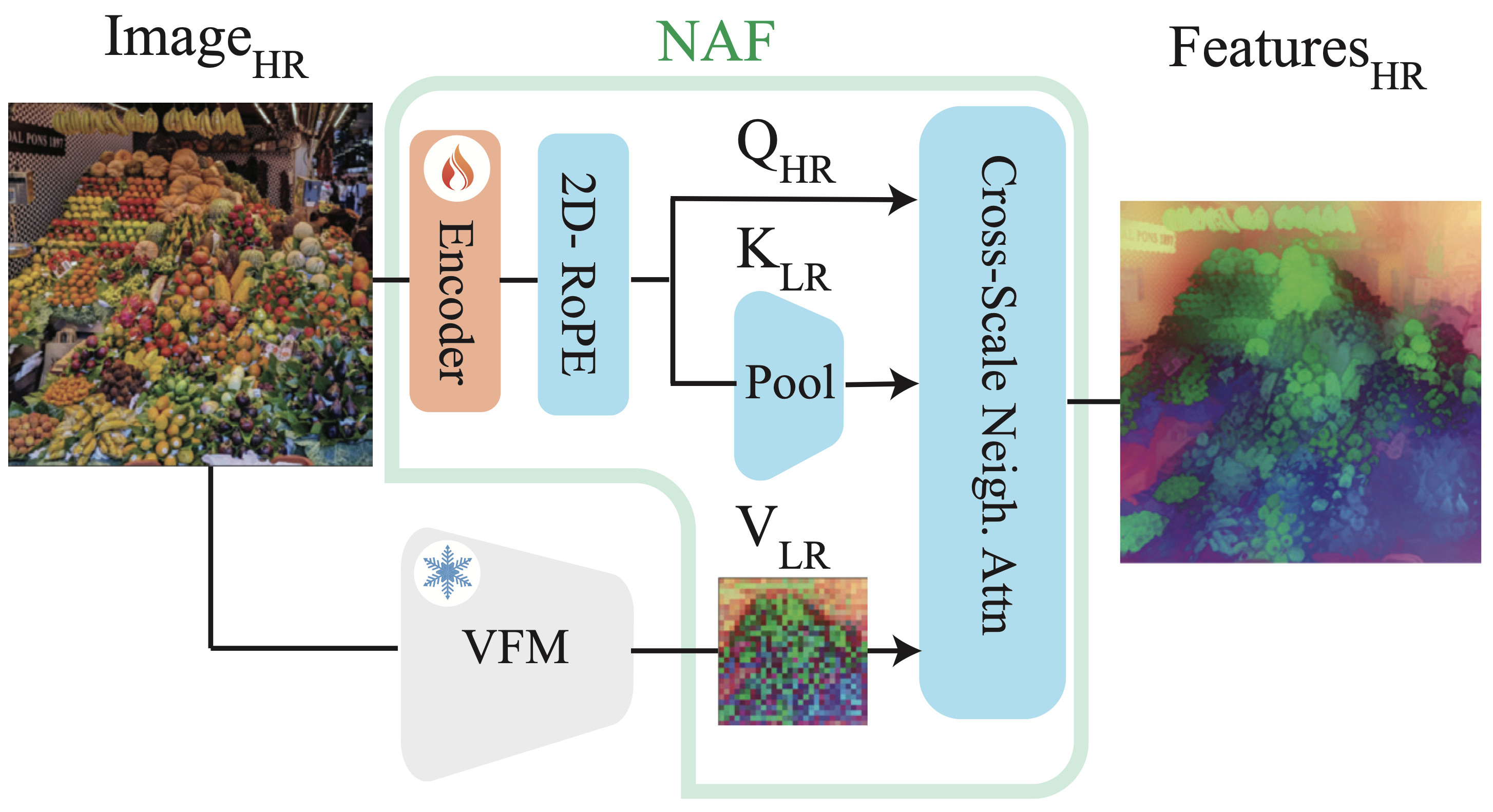
NAF: Zero-Shot Feature Upsampling via Neighborhood Attention Filtering
ArXiv Preprint

JAFAR: Jack up Any Feature at Any Resolution
NeurIPS 2025

ViLU: Learning Vision-Language Uncertainties for Failure Prediction
ICCV 2025
2024

DiffCut: Catalyzing Zero-Shot Semantic Segmentation with Diffusion Features and Recursive Normalized Cut
NeurIPS 2024
2023

VidEdit: Zero-Shot and Spatially Aware Text-Driven Video Editing
TMLR 2024
Teaching
Sep 2024 - Dec 2024
Teaching Assistant for Visual Recognition with Deep Learning at Polytech Sorbonne
- Supervised practical sessions on ConvNets, Transformers, Transfer Learning.
Open Source
Projects
PaulCouairon / DiffCut

PaulCouairon / JAFAR

valeoai / NAF

Miscellaneous
Reviewer
- CVPR 2026 (June, 2026)
- NeurIPS 2025 (December, 2025)